If you want to be kept up to date with new articles, CSS resources and tools, join our newsletter.
The Intl API in browsers has a ton of functionality around editing and formatting of text and numbers. While filling in the State of HTML survey I came across one feature I hadn't seen before: the segmenter API. Upon looking into it I found out that it allows you to break up text into segments based on the language of the text.
This caught my attention because I recently implemented a text measurement feature and I was very annoyed that I managed to only support western languages using latin characters and spaces to separate words.
I spent a lot of time with npm packages, regexes and a lot of trial and error to try and support other languages but didn't end up with a solution for them.
Enter the segmenter API.
How we use the segmenter API in Polypane
Whenever you select text in Polypane and right-click to open the context menu, we'll show you the characters, words and emoji in the text selection.
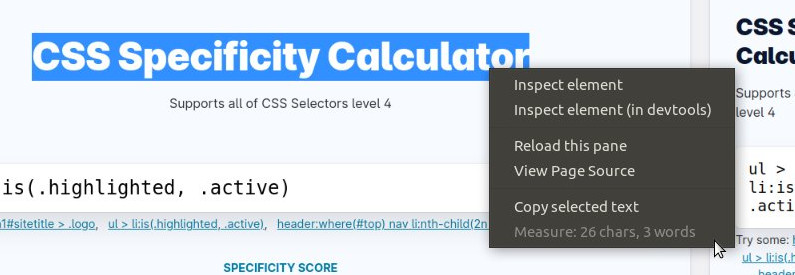
Use this to quickly check if you've written the right number of characters for a tweet, or if you've written the right number of words for a blog post.
Setting up the segmenter API
To use it, first you create a new segmenter. That takes two arguments, a language and a set of options.
const segmenter = new Intl.Segmenter('en', { granularity: 'word' });The options object has two properties, both of which can be omitted:
localeMatcherhas a value of 'lookup' or 'best fit' (default) with 'lookup' using a specific matching algorithm (BCP 47) and 'best fit' using a looser algorithm that tries to match the language as closely as possible from what's available from the browser or OS.granularityhas a value of 'grapheme' (default), 'word' or 'sentence'. This determines what types of segments are returned. Grapheme is the default and are the characters as you see them.
Then, you call segmenter.segment with the text you want to segment. This returns an iterator, which you can convert to an array using Array.from:
const segments = segmenter.segment('This has four words!');
Array.from(segments).map((segment) => segment.segment);
// ['This', ' ', 'has', ' ', 'four', ' ', 'words', '!']Each item in the iterator is an object, and it has different values depending on the granularity but at least:
segmentis the actual text of the segment.indexis the index of the segment in the original text, e.g. where it starts.inputis the original text.
For the word granularity, it also has:
isWordLikeis a boolean that is true if the segment is a word or word-like.
Sp you might have looked at the array and said "well those white spaces aren't words, are they?". And you'd be right. To get the words, we need to filter the array:
const segments = segmenter.segment('This has four words!');
Array.from(segments)
.filter((segment) => segment.isWordLike)
.map((segment) => segment.segment);
// ['This', 'has', 'four', 'words']And now we know how many actual words that sentence has.
Instead of words like the example above, you can also ask it to segment sentences, and it knows which periods end sentences and which are used for e.g. thousand separators in numbers:
const segmenter = new Intl.Segmenter('en', { granularity: 'sentence' });
const segments = segmenter.segment('This is a sentence with the value 100.000 in it. This is another sentence.');
Array.from(segments).map((segment) => segment.segment);
// [
// 'This is a sentence with the value 100.000 in it.',
// 'This is another sentence.'
// ]There are no isSentenceLike and isGraphemeLike properties, instead you can count the number of items directly.
Support for other languages
The real power is that the API doesn't just split strings on spaces or periods, but uses specific algorithms for each language. That means the API can also segment words in languages that do not have spaces, like Japanese:
const segmenter = new Intl.Segmenter('ja', { granularity: 'word' });
const segments = segmenter.segment('これは日本語のテキストです');
Array.from(segments).map((segment) => segment.segment);
// ['これ', 'は', '日本語', 'の', 'テキスト', 'です']Now to be fair, I can not read Japanese so I have no idea if this segmentation is correct, but it sure looks convincing.
Compared to string splitting or regexes, this is a lot more accurate and handles non-latin characters and punctuation correctly, needs less code and doesn't need additional checks and tests. Browsers ship with understanding of a large number of languages, so you don't have to worry about that either.
Dig into the Intl API
The Intl API has an incredible number of useful tools for creating natural language constructs like lists, dates, money, numbers and more. By and large it's easy to work with, but it uses a lot of very precise terminology that you might not be familiar with (for example, "grapheme" instead of "character", because the latter is too ambiguous), so it can be a bit daunting to get started with.
For a full overview of the API, check out our article on the Intl API. It covers the entire API with lots of demos and explanations of the different parts of the API and how to use them.
As for Polypane, you can bet the next version will have text measurement option that works across languages and also tells you the number of sentences in any text you've selected.